视频编解码简介
为什么要对视频进行编码
我们为什么要对视频进行编码呢? 要知道我们看到的视频,无论是大屏幕上的电影,还是手机上的短视频,其实都是由一张张图片组成的,为了让观看者不会感觉到卡顿,一秒钟至少需要有16张图片变换(这个一秒钟多少张图片的变换叫做帧率),一般情况下是30帧。那么按照这个方式算下来,一个1280x720分辨率的视频按照一秒钟的大小就是 1280x720x30 ≈ 420M,这仅仅是一秒钟的视频,这么大的数据量别说是在网络上传输了,就连你的硬盘恐怕也都吃不消。
所以我们需要对视频进行压缩,而压缩的过程中就需要对视频进行编码。
为什么编码后视频会变小
那为什么对视频的编码就是压缩呢?仔细想想我们平时看电影的时候,每个镜头或多或少都会有一些一段时间内不变的场景吧?这个时候每一帧都带上这个场景就造成了数据上的冗余,所以在编码过程中,就会去除这些冗余的数据。而在视频信息中一般有三种冗余信息,并且每种冗余信息都才用不同的方式处理:
- 空间冗余:采用帧内预测编码压缩
- 时间冗余:采用运动搜索和运动补偿压缩
- 统计冗余:采用熵编码压缩
软编码和硬编码
编码又分为软编码和硬编码
- 软编码:使用CPU进行编码
- 硬编码:不使用CPU进行编码,使用比如显卡GPU
那他们有什么区别呢?之前用过一些视频直播平台App的同学有可能会感受到过,使用软编码的App在直播的时候手机会明显的发烫,这就是因为在使用CPU进行软编码的时候,会对CPU的负载影响很大,导致设备发热,但是软编码也有优点,就是低码率下的质量要比直接使用硬编码好一点。不过现在在GPU硬件平台也有移植了一些优秀的软编码算法,提升低码率下硬编码的质量。
H.264简介
国际上指定视频编解码技术的组织主要有两个,并且指定了两个主要系列的编解码规则,一个是国际电联(ITU)主导的H.26X系列,一个是国际标准组织机构(ISO)主导的MPEG系列。
而H.264是两个组织的联合视频组(JVT)共同制定的数字视频标准,所以他既是ITU的H.264标准,也是ISO的MPEG-4的第10部分或者叫AVC(Advanced Video Coding)。
所以在当下H.264还是很牛*的,另外H.265作为H.264的继任者,可以支持最高8K(8192x4320)分辨率的视频编解码,也是未来发展的趋势。
VCL与NAL分层
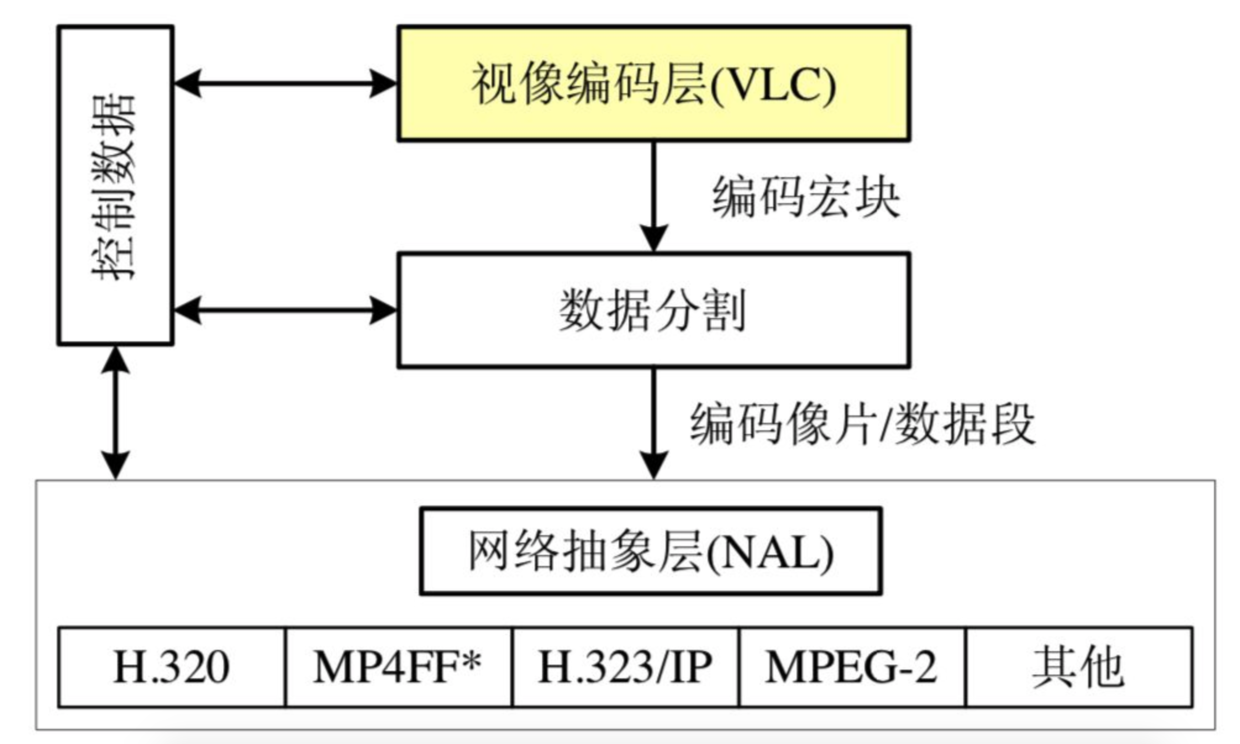
H.264的原始码流(裸流)是由一个接一个的NALU组成的,他的功能分为两部分:VCL:视频编码层,NAL:网络提取层。
VCL: 视像编码层(Video Coding Layer, 简称VCL),包括核心压缩引擎和块,宏块和片的语法级别定义,设计目标是尽可能地独立于网络进行高效的编码,对视频原始数据进行压缩。
NAL: 网络抽象层(Network Abstraction Layer,简称NAL)。在以太网每个包大小是 1500 字节,而一帧往往会大于这个值,所以就需要用于按照一定格式,对 VCL 视像编码层输出的数据拆成多个包传输,并提供包头(header)等信息,以在不同速率的网络上传输或进行存储,所有的拆包和组包都是 NAL 层去处理的。覆盖了所有片级以上的语法级别。VCL数据传输或者存储之前,会被映射到NALU中,H.264数据包含这一个个NALU
一个NALU = 一组对应于视频编码的NALU头部信息 + 一个原始字节序列负荷(RBSP,Raw Byte Sequence Payload)
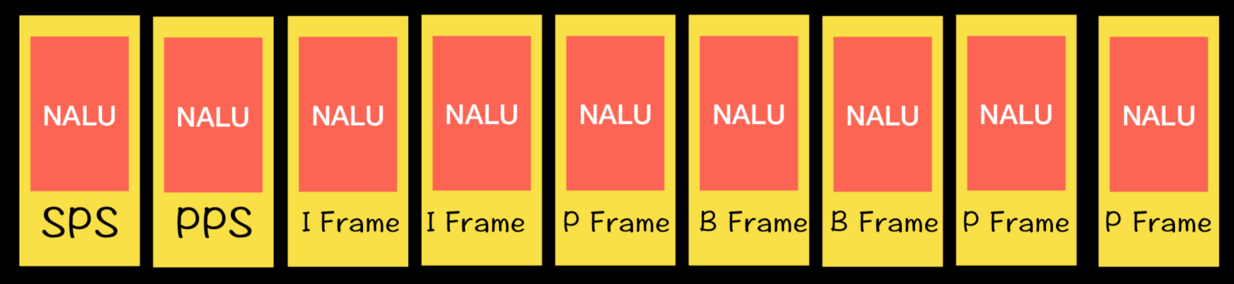
H.264码流第一个NALU是SPS,第二个NALU是PPS,第三个NALU是IDR。
*SPS: 序列参数集 SPS(Sequence Parameter Sets),存储的是一个序列的信息,包括有多少帧等
PPS: 图像参数集 PPS(Picture Parameter Sets ),存储的一帧的信息。 解码的时候必须获取到 SPS 和 PPS 的信息,才能对后面的数据进行解码。
H.264的三种帧
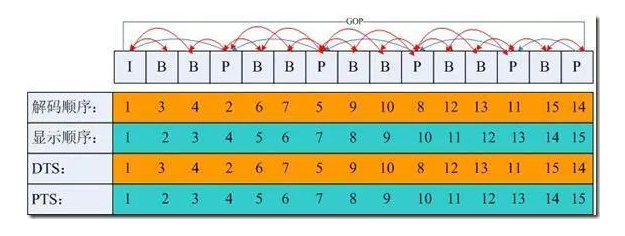
在H.264中定义了三种帧:
- I帧:完整编码的帧叫I帧,也是关键帧,上边说到的电影中有不变场景的情况中,这个帧一般是一个全新完整的场景中的
- P帧:参考之前的I帧生成的只包含差异部分编码的帧,也叫向前参考帧,P帧只会保存和之前帧不一样的数据,这样能够让数据大大减少
- B帧:参考前后编码的帧,也叫双向参考帧,压缩时要参考前后两帧,压缩率会更高,但是因为对后一帧也有依赖,所以在直播中应用时需要考虑到网络传输的速度,这时候就不是很适合使用B帧
H.264的算法
H.264采用的核心算法是帧内压缩和帧间压缩。
- 帧内压缩:生成I帧的算法
- 帧间压缩:是生成B帧和P帧的算法
在编码的过程中,H.264会把几帧图像分为一组,称为GOP(Group of Picture)或者GOF(Group of Frame)。一般情况下,一个GOP会有一个I帧,并且以这个I帧开头,然后跟随多个P帧以及B帧。
VideoToolBox
在iOS中,处理视频相关的框架有5个,从顶层开始分别是:
- AVKit
- AVFoundation
- VideoToolBox
- Core Media
- Core Video
可以看到VideoToolBox是处于中间的位置,算是相对底层的框架,可以直接访问硬件进行硬编解码。
编码(VTCompressionSession)
VideoToolBox中使用VTCompressionSession进行编码,从
VTCompressionSession官方文档中可以看出来,使用VTCompressionSession进行编码主要有5个步骤。
- 使用 VTCompressionSessionCreate 创建一个session;
- 使用 VTSessionSetProperty 或 VTSessionSetProperties 对session设置一些属性;
- 使用 VTCompressionSessionEncodeFrame 进行编码,输出的内容会在callback中返回;
- 使用 VTCompressionSessionCompleteFrames 停止编码;
- 使用 VTCompressionSessionInvalidate 和 CFRelease 来释放资源。
创建session
首先看一下创建session的函数
|
|
首先我们来看一下每个参数的作用:
- CFAllocatorRef allocator:内存构造器,传递默认的kCFAllocatorDefault即可
- int32_t width:编码器的宽度,不用多说
- int32_t height:编码器的高度,也不用多说了
- CMVideoCodecType codecType: 编码器的类型,如果使用H264的话,我们选择kCMVideoCodecType_H264就可以了
- CFDictionaryRef encoderSpecification:编码规范,这边我们直接传NULL就可以了;
- CFDictionaryRef sourceImageBufferAttributes:图像缓冲区属性,这里同样传递NULL即可;
- CFAllocatorRef compressedDataAllocator:编码后数据的构造器,传NULL
- VTCompressionOutputCallback outputCallback:编码结束后的回调函数
- void outputCallbackRefCon:回调函数的参数,一般传`(__bridge void )(self)`或者指定的处理回调方法的类
- VTCompressionSessionRef *compressionSessionOut;输出参数,传递一个session
配置参数
同样的,先看一下配置参数的方法:
|
|
这个就好理解多了,
- VTSessionRef session:编码器;
- CFStringRef propertyKey:需要设置的property的key
- CFTypeRef propertyValue:需要设置的property的value
可以配置的参数有很多,具体的内容都可以参考官方文档Compression Properties | Apple Developer Documentation。
这里简单说几个(当然了,具体使用还是要看你的项目,这里说的是我的项目里用到的)
- kVTCompressionPropertyKey_ProfileLevel 编码比特流的级别
- kVTCompressionPropertyKey_RealTime 是否在运行时实时执行压缩
- kVTCompressionPropertyKey_ExpectedFrameRate 期望的帧率,注意这里的期望并不一定能够达到
开始编码
开始编码简单一些,就直接调用方法传递session即可:
|
|
回调
接下来通过回调获取到编码的参数
|
|
还是先看一下各个参数:
- void *outputCallbackRefCon 刚刚传递过来的参数,因为是C函数,所以不能直接使用本类中的变量,所以一般通过这个来过渡
- void *sourceFrameRefCon
- OSStatus status 编码的状态,如果为noErr(0)表示没有异常
- VTEncodeInfoFlags infoFlags
- CMSampleBufferRef sampleBuffer 回调的buffer参数
一般情况下,我们会在这里解析回调的数据,提取出sps和pps,然后循环nalu数据来获取编码后的数据,具体的代码我会写在下边。
结束
结束编码之后,记得回调关闭session和释放之前开辟的session
|
|
完整代码:
接下来贴下编码部分的完整代码,比较少就不另外写Demo了
.h:
.m:
解码
解码和编码基本没有太大差别,VTDecompressionSession | Apple Developer Documentation官方文档中还是很清楚的写出了基本的几个步骤:
- 使用 VTDecompressionSessionCreate 创建一个解码器;
- 使用 VTSessionSetProperty 或 VTSessionSetProperties 来配置参数
- 调用 VTDecompressionSessionDecodeFrame 来开始解码
- 使用 VTDecompressionSessionInvalidate 和 CFRelease 来释放参数
接下来还是一步一步来看一下:
创建解码器
首先还是来看一下调用的方法:
|
|
可以看到解码的参数和编码基本没太大区别:
- CFAllocatorRef allocator:构造器,传默认的即可 kCFAllocatorDefault
- CMVideoFormatDescriptionRef videoFormatDescription:数据的格式
- CFDictionaryRef videoDecoderSpecification:解码器规范,同样传递NULL即可
- CFDictionaryRef destinationImageBufferAttributes:NULL
- const VTDecompressionOutputCallbackRecord * outputCallback:回调函数
- VTDecompressionSessionRef * decompressionSessionOut:session
配置参数
解码器的参数配置和编码器的方法一样,只是可能传递的参数有所不同,这里就不多做介绍,可以直接看Decompression Properties | Apple Developer Documentation
开始解码
解码的时候有一点需要注意,我们需要根据传递过来的是否为关键帧或者sps及pps,来做不同的处理,这一块可以等下直接看代码
解码的回调
解码的回调中可以收到解码成功的CVPixelBufferRef。
完整代码
接下来贴下完整的代码:
|
|
.m
最后
以上就是iOS中使用VideoToolBox来进行硬编解码的全部内容了,本来是想要在项目中为了避免内存使用过高才使用它(项目中需要在ReplayKit2的Extension中使用,有50M的内存限制),但是发现他不能在后台运行!这下就根本没法用了。
所以也就简单记录一下,没有太多的深入研究,仅供个人学习使用,如果有什么地方写的不对或者有更好的建议,欢迎各位大佬批评指正。
参考文档
VideoToolbox | Apple Developer Documentation
Apple 平台下的 VideoToolBox 框架 | Enki’s Notes
音视频学习(二)— H.264编码原理 - 掘金
直播一:H.264编码基础知识详解 - 紫忆 - 博客园
VideoToolbox使用说明 - 简书